

WordPress occupe une part très importante dans l’usage des CMS à l’heure ou j’écris ce billet (62%). Voilà ce qui peut l’expliquer à mon sens :
- Simple d’utilisation côté utilisateur
- Plutôt simple côté développeur
- Un nombre incalculable de thèmes et de plugins sont à disposition (communauté conséquente).
Mais il a aussi les défaut de ses qualités :
- Côté utilisation de ressources énergétiques (serveur), WordPress est une catastrophe… Surtout dès qu’on lui ajoute des plugins (qui n’en ajoute pas ?).
- Côté sécurité, il est très attaqué (car très utilisé). Le sport préféré des hackers, c’est le brute force…
Je vais tâcher de balayer ici mes trucs pour transformer un wordpress énergivore en wordpress sobre et sécurisé 🙂
Transformer en site statique (parfait pour les sites vitrines)
Un site « statique » c’est quoi ? C’est un site ou le code est uniquement exécuté sur le client et le serveur ne fait rien d’autre que « servir la page ». Alors qu’un site dynamique par opposition (sous wordpress pour l’exemple) va générer des pages « à la volée » et donc utiliser des ressources sur le serveur.
Mon parti-pris, c’est de convertir le wordpress « visible pour les visiteurs » en site statique « html ». L’utilisateur continue d’utiliser / d’alimenter son site via l’interface (bien faite et connue) wordpress, mais le visiteur lui ce qu’il voit c’est un site « html », sans aucun code dynamique (php ici) exécuté. De cette façon :
- Le site est inattaquable par les hackers/spameurs, il n’y a plus de code dynamique, donc plus de moyen de corrompre le site / le serveur
- L’affichage pour le visiteur est beaucoup plus rapide.
- Le serveur consomme beaucoup moins de ressources (moins d’électricité, plus petit serveur…).
- Les utilisateurs qui connaissent déjà wordpress ne sont pas bouleversés / impactés par cette optimisation.
Pour cela j’utilise un plugin wordpress qui s’appelle wp2static. Voici la structure du répertoire « web » qui est la racine du site :
- /wp/ : site wordpress avec le plugin wp2static. Adresse utilisée par l’administrateur du site pour faire ces modifications
- /static/ : le site statique généré par le plugin
- /.htaccess : contient les redirections pour que le visiteur ne voit pas de différence
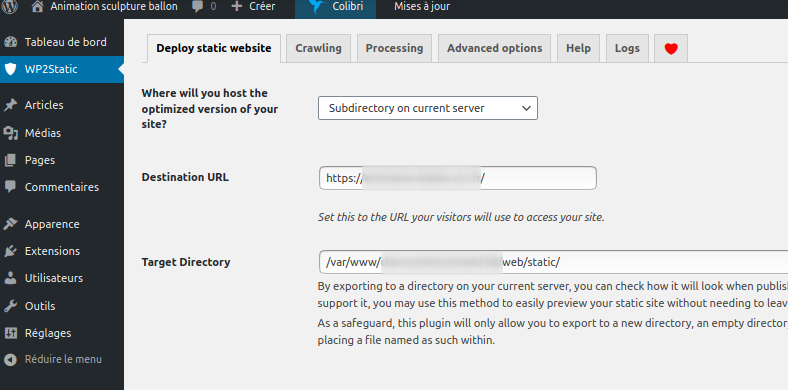
Dans le wordpress installé dans /wp/ rendez -vous dans wp2statics et configuré :
- Where will you host the optimized version of your site? : Subdirectory
- Destination URL : http://votresite.fr/
- Target Directory : /var/www/votreiste.fr/web/static/
Puis dans l’onglet Crawling indiqué :
- Exclude certain URLs :
- /wp/
- /wp-content/uploads/
- /wp-admin/
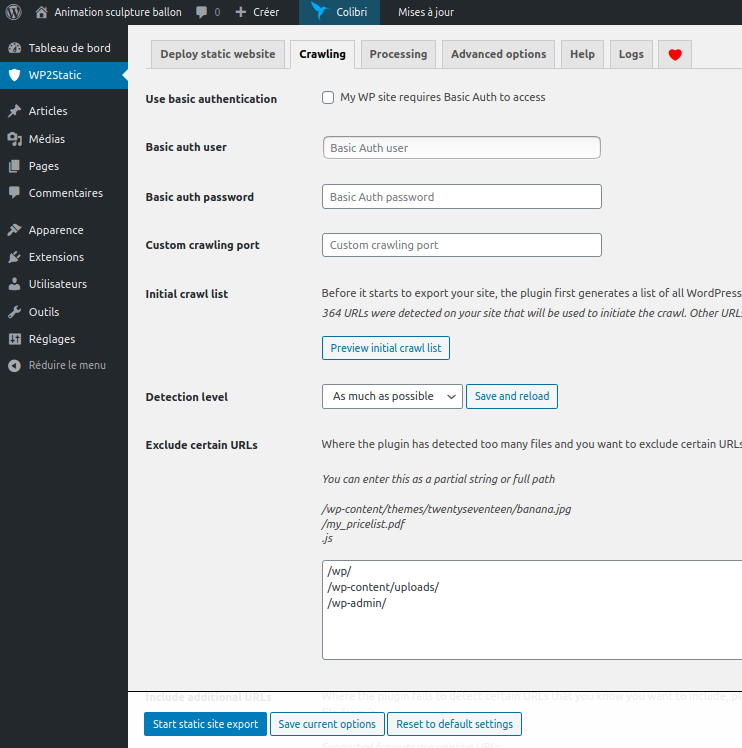
Quand c’est fait, vous pouvez cliquer sur Start Static Export.
Ajouter dans votre configuration apache ou dans un .htaccess à la racine du site :
RewriteEngine on
# Pas de ré-écriture pour le contenu uploadé (images,
RewriteRule ^/wp-content/uploads/(.*)$ /wp/wp-content/uploads//$1 [L]
# Rediriger toutes les requêtes vers /static sauf quand l'accès est souhaité sur le site wordpress original (/wp)
RewriteCond %{REQUEST_URI} !^/wp/
RewriteRule ^(.*)$ /static/$1 [L]Inconvénient majeur de ce type de « transformation » en site full static
- A chaque modification l’utilisateur doit penser à re-générer le site statique
- Ce point peut être amélioré avec l’usage du plugin wp-cli et un petit script… https://wp2static.com/developers/wp-cli/
- Le contenu dynamique (formulaire de contact / commentaire) est impossible :
- Pour les commentaires, c’est possible avec des commentaires chargés en Javascript, typiquement HashOver Next (alternative auto-hébergable à DISQUS). J’ai fait un script de migration WordPress > HashOver : wp2hashover
- Pour les commentaires, il est possible d’utiliser des formulaires en iframe ou formulaire javascript/ajax
Transformer en (presque) site statique (W3 Total Cache)
La solution wp2static n’était pas complètement satisfaisante et j’ai continué mes recherches. En testant le plugin W3 Total Cache, je me suis aperçu qu’il faisait exactement ce que je cherchais à faire et même plus !
Après paramétrage, j’ai trouvé ceci dans le fichier .htaccess :
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
[...]
RewriteCond %{REQUEST_METHOD} !=POST
[...]
RewriteCond "%{DOCUMENT_ROOT}/wp-content/cache/page_enhanced/%{HTTP_HOST}/%{REQUEST_URI}/_index%{ENV:W3TC_SSL}%{ENV:W3TC_PREVIEW}.html%{ENV:W3TC_ENC}" -f
RewriteRule .* "/wp-content/cache/page_enhanced/%{HTTP_HOST}/%{REQUEST_URI}/_index%{ENV:W3TC_SSL}%{ENV:W3TC_PREVIEW}.html%{ENV:W3TC_ENC}" [L]
</IfModule>Pour résumer, ce que font les règles c’est :
- Si la page HTML static a été générée (le fichier existe) dans /var/www/decroissant-au-beurre.com/web/wp-content/cache/page_enhanced/decroissant-au-beurre.com/services/_index_ssl.html (pour l’appel à https://decroissant-au-beurre.com/services/ alors on l’appelle directement (pas d’exécution de code PHP… ) SINON on appelle la page « normale » dans wordpress et celui-ci génère la page de cache /static pour le prochain visiteur
- Dès qu’il y a une requête POST, le cache n’est pas appelé. Donc tous les formulaires restent compatibles avec le cache et seules les pages de résultats ne seront pas tirées du cache.
Ca veut dire qu’a performance égale avec la solution précédente, ce plugin fait mieux car il gomme les défauts précédents et permet de continuer d’utiliser des formulaires/les commentaires.
C’est parfait ! Le cache peut aussi être stocké via memcache et non sur disque (ce qui rend l’accès / l’affichage encore plus rapide (d’autres technologies possibles : APC / Xcache…)
Les fonctionnalités supplémentaires :
Minifier : diminuer trafic réseau
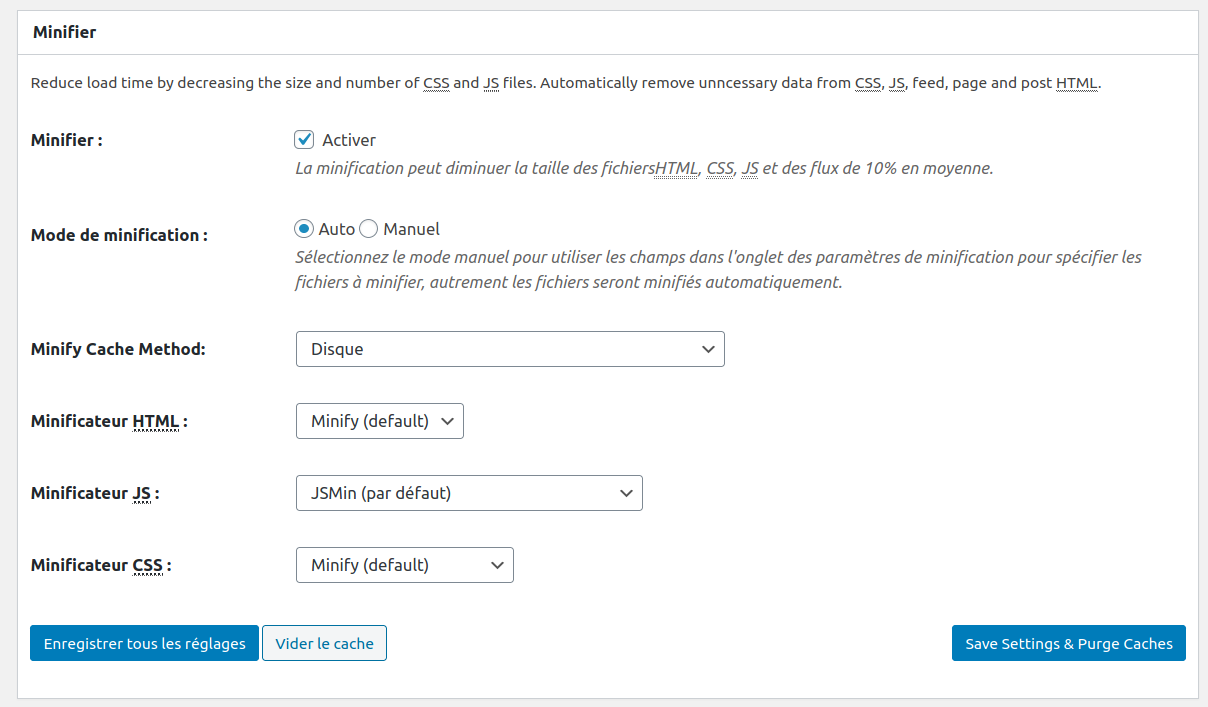
W3 Total Cache propose une fonctionnalité de Minification
minifier signifie réduire la taille du code. C’est un processus très utilisé en programmation web pour réduire la taille d’un programme à télécharger depuis un serveur et ainsi réduire l’encombrement du réseau. Cela peut aussi être considéré comme une forme d’offuscation du code.
Pour cela on supprime tous les commentaires et les espaces qui ne gêneront pas le bon fonctionnement de l’application. On remplace aussi le nom des variables interne à l’application pour les réduire à un seul ou deux caractères. Il est aussi possible d’utiliser certaines écritures compactes propres aux langages (couleur en hexadécimal, raccourcis…)
https://fr.wikipedia.org/wiki/Minification
Si on analyse le code après avoir activé la Minification on observe :
<!DOCTYPE html><html lang=fr-FR><head><script>window.w3tc_lazyload=1,window.lazyLoadOptions={elements_selector:".lazy",callback_loaded:function(t){var e;try{e=new CustomEvent([...]Alors qu’un site non-minifié donne plutôt :
<!DOCTYPE html>
<html lang="fr-FR">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="stylesheet" id="extend-builder-css-css" href="assets/static/css/theme.css" type="text/css" media="all">
<style id="extend-builder-css-inline-css" type="text/css">
/* page css */
/* part css : theme */
.h-y-container > *:not(:last-child), .h-x-Vous pouvez minifier tout ou partie du code (HTML/ CSS / Javascript…). Certains plugins peuvent ne plus fonctionner à cause de la minification. Il est donc important de tester votre site après avoir activé ces options.
Lazy Loading : Afficher les images au besoin
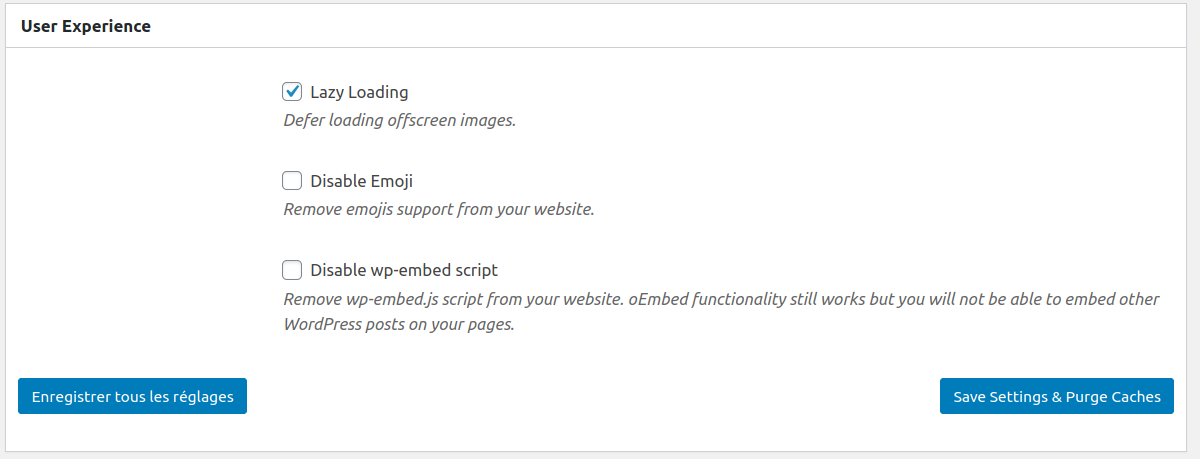
Si vous avez un site très long, il est possible que des images soient présentes en bas de page. Il est pertinent de ne charger ces pages qu’au besoin (que si vous allez jusqu’en bas de la page). Et bien la fonction Lazy Loading permet cela.
Cette fonctionnalité permet aussi un gain non négligeable de bande passante.
Mise en cache navigateur
Vous pouvez améliorer les entêtes navigateurs en spécifiant à celui-ci des dates d’expiration de fichier. De cette façon il ne va pas retourner charger la/les pages sur le serveur en cas de nouvelles visites.
Mesures performance
Voilà un stress test (envoi de requêtes massives) du même site avec ou sans génération en site statique (fait avec W3 total cache ici) :

WordPress sans optimisation 
Avec cache/transformé en statique
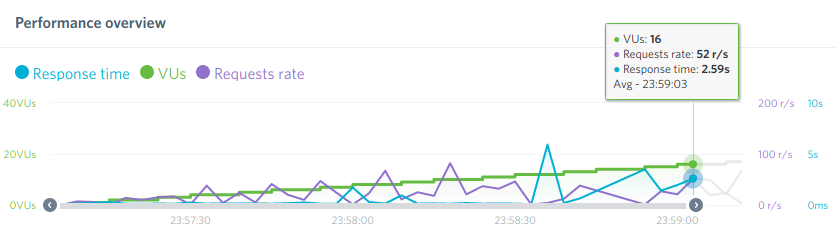
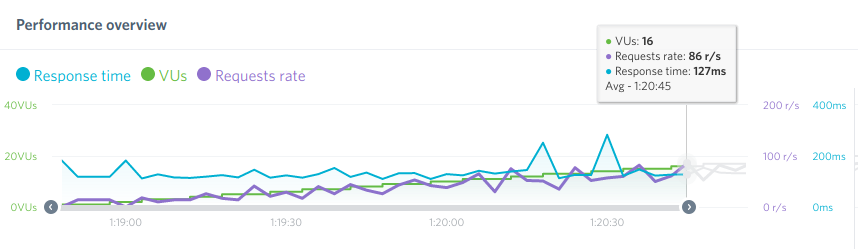
On constate que c’est 20 fois plus rapide à l’affichage et que c’est plutôt constant. Est-ce que c’est 20 fois moins énergivore ? ça c’est difficile à mesurer mais c’est forcément moins…
Voici ci-après le poids de chargement d’une même page sans optimisation et avec Lazy Loading + Minification

Sans optimisation : 21,5 Avec Minification + Lazy : 3,9Mo
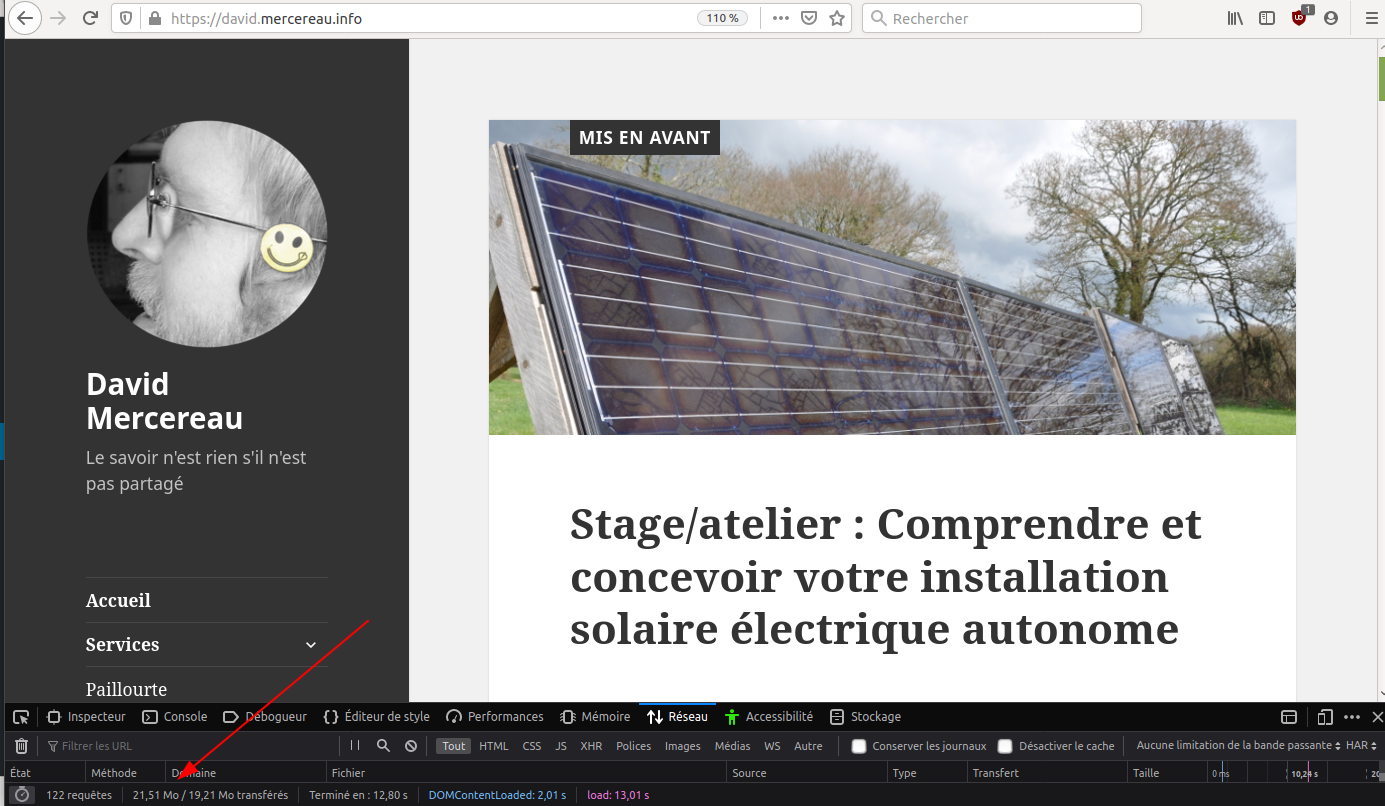
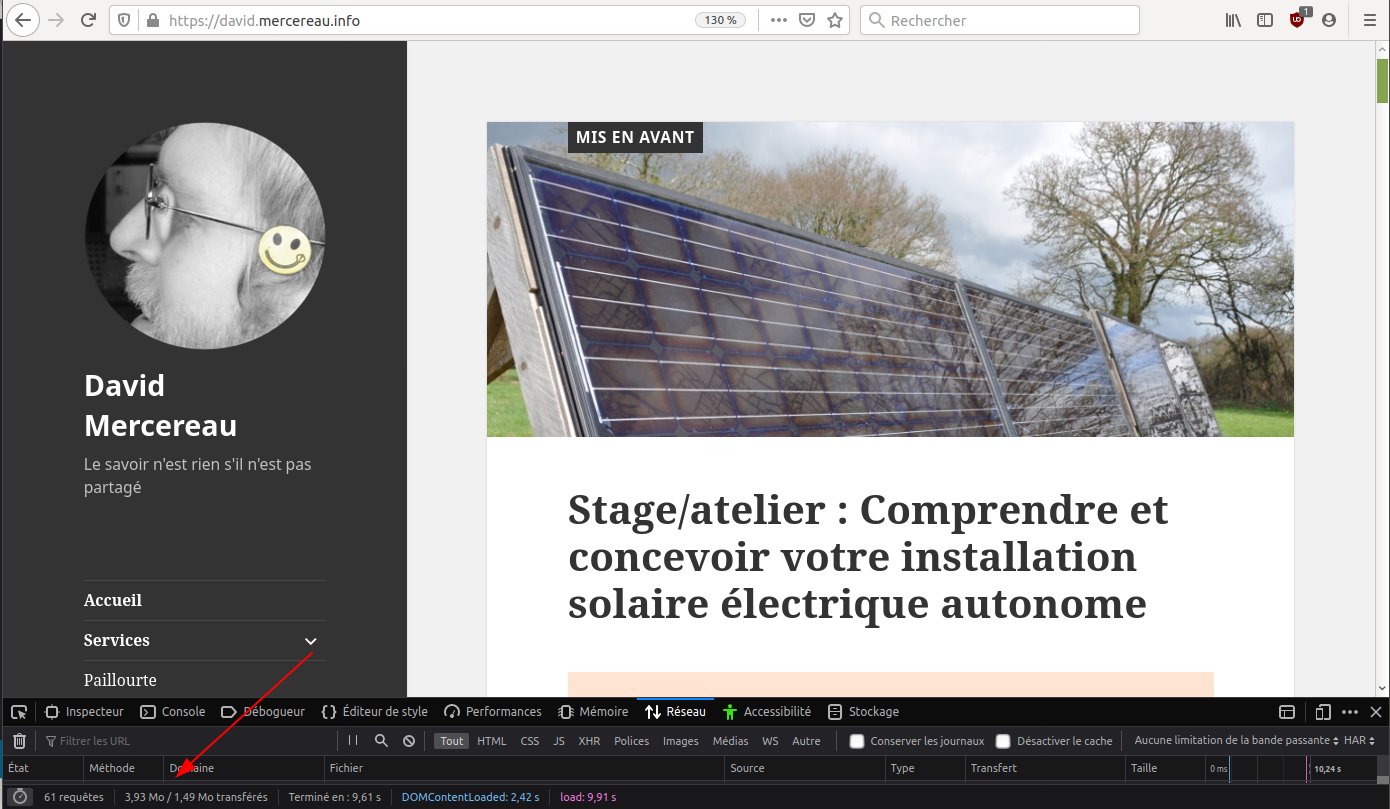
- Sans optimisation : 21,5Mo
- Avec Minification et Lazy : 3,9Mo
Soit 5,5 fois moins lourd…
Sécurité
Le minimum pour sécuriser un wordpress c’est :
- Faire les mises à jour (de nombreux plugins existent pour automatiser cela)
- Ne pas utiliser « admin » en nom d’utilisateur admin
- Avoir des mots de passe forts
- Bloquer les tentatives de brutes forces :
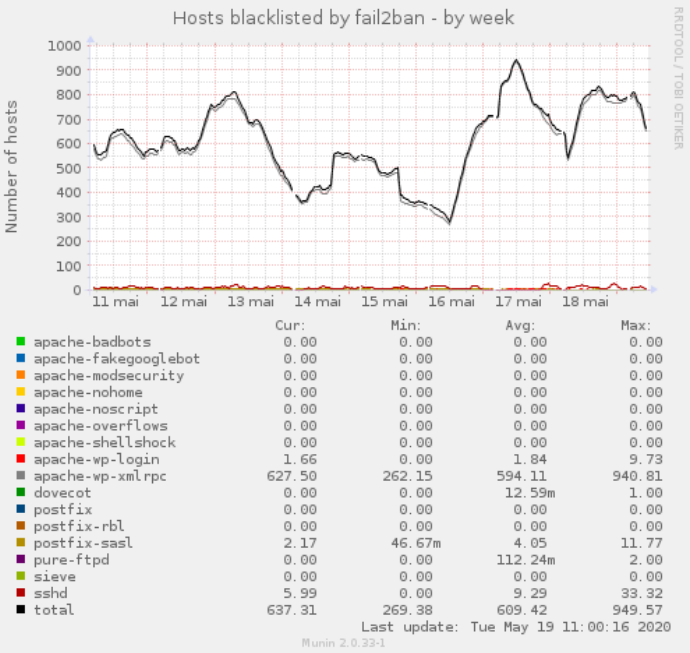
WordPress se fait pas mal attaquer du fait qu’il soit populaire. La principale attaque (hors SPAM sur les commentaires) est faite par brute-force sur la page wp-login.php et xmlrpc. J’ai consacré un article dédié pour intégrer les logs de WordPress dans Fail2ban, et ainsi pouvoir bloquer les tentatives au niveau firewall : WordPress & fail2ban : stopper la brute-force « POST /wp-login.php » (uniquement possible sur un hébergement dédié). C’est particulièrement efficace comme vous pouvez le voir sur ce graphique :
Gestion serveur mutualisé
Si vous gérez un serveur mutualisé, vous pouvez déployer le plugin de cache et faire les mise à jour de tous les wordpress installé sur votre serveur avec wp-cli-isp (taillé pour les serveurs sous ISPconfig, mais c’est adaptable)





















{kind=link}