
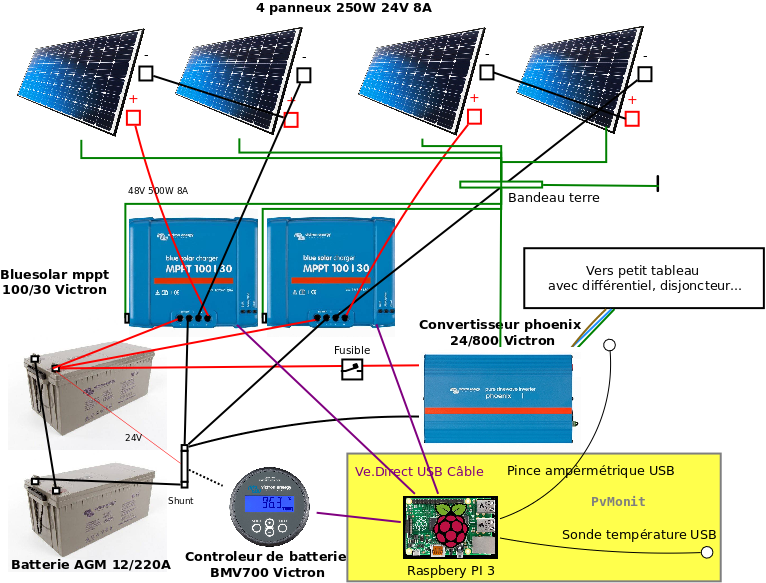
Contexte : besoin de historiser les configs système à plusieurs
Administrer un serveur Linux à plusieurs (co-administration) peut rapidement tourner au casse-tête si on ne garde pas de trace des modifications «
Qui qu’a modifié le main.cf ? Pourquoi ? Elle était super ma config
Le service ne redémarre pas : qu’est-ce qui c’est passé depuis ma dernière connexion ?
C’est un problème que j’ai rencontré aussi bien dans un contexte associatif (serveurs de retzien.fr) que professionnel (infrastructure retzo.net). Lorsqu’un service tombe en panne du jour au lendemain, on entend souvent « mais pourquoi ça ne marche plus alors que ça marchait hier ? » ou « qui a fait ce changement, et pourquoi ? » Faute de trouver un outil existant correspondant à mes besoins ( et après en avoir discuté sur le forum CHATONS), j’ai développé sysgit, un petit outil shell open source conçu pour versionner les fichiers de configuration système et possiblement multi-admin.
Pourquoi utiliser Git pour les fichiers de configuration ?
Git est un système de gestion de versions largement utilisé par les développeurs, mais il s’applique tout aussi bien aux fichiers de configuration. L’idée est d’enregistrer chaque modification apportée aux configs dans un dépôt Git, avec un historique clair. On peut ainsi commenter chaque changement, comparer les différences, et revenir en arrière en cas de besoin. En administration système collaborative, Git apporte surtout de la visibilité sur qui a changé quoi et quand. Chaque admin peut suivre l’évolution des fichiers critiques, ce qui facilite le débogage et la communication au sein de l’équipe. En somme, versionner ses configs, c’est s’assurer une forme de documentation et d’audit continu, plutôt que de subir des modifications non tracées. Coupler à un outil comme gitlab/redmine ou autre qui gère aussi les issus/tickets ça permet d’avoir le volet « projet/tâche » relier aux différentes actions / modifications du/des serveurs
Il existe déjà un outil dédié nommé etckeeper qui permet de versionner le répertoire /etc avec Git. Cependant, etckeeper se limite à /etc et ne gère pas facilement d’autres chemins du système. C’est justement cette limite qui a motivé la création de sysgit.
Présentation de sysgit
sysgit est un script shell (bash) qui facilite le suivi de configuration sur un serveur en s’appuyant sur Git. En bref, sysgit c’est :
- Un wrapper Git multi-chemins : il versionne plusieurs chemins/fichiers de configuration du système dans un dépôt unique, au lieu d’un dépôt par répertoire.
- Aucun déplacement de fichiers : le work-tree utilisé par Git est la racine du système (/), ce qui évite de devoir déplacer vos fichiers ou utiliser des liens symboliques. On ne suit que les chemins que l’on ajoute explicitement au dépôt.
- Historique clair et centralisé : l’objectif est de garder un journal de modifications lisible de toutes les configurations « sensibles » du système, sans déployer d’outil lourd de gestion de config (on reste sur du Git pur). En pratique, l’historique des commits fait office de log des changements sur le serveur.
Techniquement, sysgit ne réinvente rien : il s’appuie sur Git. Les commandes sysgit ne font que lancer git avec les bons paramètres de répertoire (options –git-diret –work-treeajustées). Cela signifie que le dépôt Git de configuration est stocké à part (en dehors de vos dossiers système) et que vous pouvez toujours interagir avec lui via Git standard au besoin.
Fonctionnalités principales de sysgit
Comparé à etckeeper ou à un usage “manuel” de Git, sysgit apporte plusieurs fonctionnalités utiles :
- Scope étendu : on peut suivre tous les fichiers de configuration importants du système, pas juste /etc. Par exemple, libre à vous d’inclure /opt/monapp/config.yml, /var/spool/cron/crontabs, /root/.ssh/authorized_keys, etc.
- Dépôt unique : un seul dépôt Git centralise l’historique de tous ces chemins. Inutile de multiplier les dépôts ou de gérer des symlinks pour différents dossiers.
- Sélection fine des fichiers : vous ajoutez explicitement les chemins à versionner (whitelist) plutôt que de tout versionner en bloc. Vous ne suivez ainsi que ce qui vaut la peine d’être historisé (configs critiques), ce qui allège l’historique. Mais vous pouvez aussi ajouter tout un répertoire (/etc par exemple si vous le souhaitez)
- Profils multi-admin : sysgit gère plusieurs profils d’auteurs Git, très pratique sur un serveur administré à plusieurs. Concrètement, si un admin effectue un commit en root il choisie « qui il est » (son identité) et celle-ci est conserver tel une sessions le temps de sa connexion.
root@srvmail:~# sysgit status
Choisir un profil:
1) David - david.*********@retzien.fr
0) Creer un nouveau profil
Votre choix: 0
Nom: Serge
Email: serge.*********@retzien.fr
Sur la branche master
Modifications qui ne seront pas validées :
(utilisez "git add <fichier>..." pour mettre à jour ce qui sera validé)
(utilisez "git restore <fichier>..." pour annuler les modifications dans le répertoire de travail)
modifié : ../etc/sympa/sympa_transport
modifié : ../etc/sympa/sympa_transport.db
aucune modification n'a été ajoutée à la validation (utilisez "git add" ou "git commit -a")
root@srvmail:~# sysgit add /etc/sympa/sympa_transport*
En tant que Serge <serge.*********@retzien.fr> (preciser -p pour changer)
root@srvmail:~# sysgit commit -m "Suppressoin de mailing liste"
En tant que Serge <serge.*********@retzien.fr> (preciser -p pour changer)
sending incremental file list
root@srvmail:~# sysgit log
En tant que Serge <serge.*********@retzien.fr> (preciser -p pour changer)
commit 428bb2401993b91e90a4dabac53d8d129fb378b4 (HEAD -> master)
Author: Serge <serge.*********@retzien.fr>
Date: Tue Jan 20 10:07:22 2026 +0100
Suppressoin de mailing liste
commit e952c0fd43317cba8afead584b7933621eb307f7
Author: David <david.*********@retzien.fr>
Date: Tue Jan 20 09:37:19 2026 +0100
Changement éditeur par défaut
- Intégration d’etckeeper : un script de migration est fourni pour importer l’historique existant d’un dépôt etckeeper, si vous utilisiez déjà cet outil. Vous pouvez ainsi passer à sysgit sans perdre vos anciens historiques de /etc.
- Auto-commit programmable : sysgit peut s’utiliser avec un timer systemd afin d’automatiser un commit chaque nuit (pour capturer les changements éventuels qui n’auraient pas été committés manuellement).
- Hook APT/dpkg : un hook est prévu pour effectuer automatiquement un commit dès qu’une installation ou mise à jour de paquet modifie des fichiers de config (similaire à ce que fait etckeeper). Cela garantit que même les changements induits par les paquets sont tracés sans intervention manuelle.
- Rappel en fin de session : enfin, sysgit peut rappeler à l’administrateur de committer les modifications non sauvegardées lors de sa déconnexion (bash logout) s’il en détecte. Ce petit mémo évite d’oublier de versionner un changement avant de fermer sa session.
- Mise à jour facile : petit coquin je vous connais, trop la flemme de mettre à jour des petits outils comme ça qui sont pas dans un package apt (je parle pour moi). Ici rien de plus facile : sysgit -u
Installation de sysgit
L’outil sysgit étant tout récent, il n’est pas (encore) empaqueté dans les distributions. Son installation reste malgré tout simple :
- Prérequis : assurez-vous d’avoir Git installé sur le serveur (sudo apt install git sur Debian/Ubuntu si nécessaire).
- Installation rapide par script : mais vous pouvez préférer récupérer le projet depuis Framagit :
wget -O /tmp/sysgit-install.sh https://framagit.org/kepon/sysgit/-/raw/main/install.sh
sudo bash /tmp/sysgit-install.sh
Utilisation typique de sysgit
Une fois l’installation effectuée, l’utilisation de sysgit se rapproche de celle de Git, avec quelques commandes dédiées. Voici un mini-tutoriel d’usage courant :
# 1. Initialiser le dépôt "système" (une seule fois au départ)
sysgit init
# 2. Choisir les fichiers/répertoires à versionner
sysgit add -A /etc # par exemple tout /etc
sysgit add /root/.bashrc # fichiers de conf utilisateur
sysgit add /var/spool/cron/crontabs # répertoire de crons
... # (ajoutez autant de chemins que nécessaire)
# 3. Vérifier l'état et enregistrer l'état initial
sysgit status # liste les modifications en attente (fichiers ajoutés)
sysgit commit -m "État initial" # crée le premier commit avec tous ces fichiers
echo "# Modification d'un fichier suivi" >> /root/.bashrc
sysgit diff # affiche les différences
Une fois ce dépôt initialisé avec vos configs de base, au quotidien ça consiste simplement à committer toute modification de configuration. Par exemple, si vous modifiez /etc/ssh/sshd_config, vous exécuterez ensuite sysgit status (pour voir les changements non committés), éventuellement sysgit diff (pour visualiser les différences), puis sysgit commit -m « Msg » pour valider la modification dans l’historique. Vous pouvez bien sûr pousser le dépôt vers un serveur Git distant (Gitea, GitHub, etc.) pour sauvegarde ou partage, via les commandes usuelles (sysgit remote add origin …, sysgit push).
Pour la consultation, sysgit expose toutes les commandes Git classiques : sysgit log pour l’historique des commits, sysgit show <commit> pour détailler un commit précis, sysgit checkout <commit> — <fichier> pour restaurer une ancienne version d’un fichier, etc. En interne, “c’est du Git normal” – vous bénéficiez donc de toute la puissance de Git pour naviguer dans l’historique.
Mémo des commandes sysgit
Voici un récapitulatif des principales commandes fournies par sysgit :
- sysgit init – Initialiser un nouveau dépôt de configuration (à exécuter une fois par serveur).
- sysgit add <chemin> – Ajouter un fichier à suivre (peut être répété pour chaque élément à versionner).
- sysgit add -A <chemin> – Ajouter un répertoire à suivre
- sysgit status – Afficher les modifications non committées (équivalent de git status).
- sysgit diff – Afficher les différences entre les fichiers suivis et la dernière version committée.
- sysgit commit -m « Message » – Enregistrer (committer) les changements avec un message descriptif.
- sysgit log – Consulter l’historique des commits (qui a changé quoi et quand).
- sysgit show <SHA> – Afficher le détail d’un commit (identifié par son hash ou identifiant).
- sysgit checkout <SHA> –– <fichier> – Restaurer un fichier suivi à l’état qu’il avait lors d’un commit donné (pratique pour annuler une modification).
- sysgit push / sysgit pull – Envoyer ou récupérer les changements vers/depuis un dépôt Git distant (si configuré, pour sauvegarde ou partage entre admins).
(Toutes les autres commandes Git peuvent être utilisées via sysgit de la même manière, en passant simplement par l’alias sysgit.)



















{kind=link}