C’est un peu la succession, l’amélioration de mon service de sauvegarde à froid, ça va maintenant plus loin, c’est plus « user freindly ». Je le propose avec mon activité pro « retzo.net » :
Le stockage à froid qui s’allume uniquement si vous en avez besoin.
Le constat est simple : la majeure partie des données numériques en ligne n’a aucunement besoin d’être accessible à tout instant et pourtant elle occupe une place conséquente sur des serveurs (coût énergétique, environnemental…)
Les données numériques que nous stockons ont un coût énergétique souvent sous-estimé. Les datacenters, où sont hébergés bon nombre de sauvegardes et de services en ligne, représentent environ 1 % de la consommation électrique mondiale (source). Pour des associations ou entreprises éco-responsables engagées dans une démarche de sobriété numérique, il est donc crucial de repenser la façon dont on stocke et sauvegarde les données. Le stockage à froid s’impose comme une solution incontournable pour réduire drastiquement l’empreinte énergétique de vos sauvegardes tout en gardant vos données en sécurité.
🌍 Les serveurs matériels utilisés sont très basses consommations (architecture ARM, disque SSD)
♻️ Les serveurs (hors disque dur) sont issus du ré-emploi
☀️ L’énergie utilisée prioritairement est le solaire
Et exclusivement si vous le souhaitez
🔒 Vos données sont en sécurité, le service étant hors ligne la majorité du temps, la surface d’attaque est bien moindre
Chiffrement de la communication (inclus)
Chiffrement du disque possible
Serveur dédié possible
⏳ L’accès à vos données, l’allumage du serveur est possible via une interface web et/ou des protocoles standard (SFTP, RSYNC (over ssh), WebDAV, BORG) authentification par mot de passe ou par clé
Le stockage à froid consiste à conserver des données (sauvegardes, archives, etc.) sur un support qui n’est alimenté et allumé qu’en cas de besoin. Contrairement à un serveur classique qui tourne en continu 24h/24, un système à froid reste hors tension la majeure partie du temps. Concrètement selon le cas :
Service de sauvegarde : le serveur est démarré uniquement lors des opérations de sauvegarde ou de restauration, puis éteint dès qu’il a fini son travail. On évite ainsi de faire tourner des disques et des serveurs inutilement le reste du temps.
Vous disposez d’une interface pour allumer manuellement celui-ci pour restaurer des données au besoin
Service d’archivage : le serveur est éteint systématiquement et vous l’allumez sur demande via une interface web pour accéder à vos données, en ajouter, en supprimer…
En résumé, le stockage à froid c’est :
Allumé uniquement à la demande : le système de sauvegarde fonctionne seulement au moment nécessaire (sauvegarde programmée, restauration exceptionnelle), le reste du temps il consomme 0 watt.
Matériel sobre en énergie, issu du ré-emploi : il s’appuie sur un mini-ordinateur à très faible consommation (Raspberry Pi) couplé à des disques SSD. Ce type de dispositif consomme environ 3 watts en activité, soit l’équivalent d’une très petite ampoule LED.
Stockage déporté : généralement, le support de sauvegarde se trouve hors du site principal, ce qui protège vos données en cas d’incident (incendie, vol, panne majeure) sur votre infrastructure principale.
Auto-hébergement en France: la solution est hébergée hors datacenter ce qui diminue le coût environnemental infrastructure, climatisation (obligatoire en cas de concentration de serveur) ici les places seront limitées pour éviter d’avoir à recourir à de la climatisation.
Adopter le stockage à froid pour vos sauvegardes permet de réduire la consommation électrique d’un facteur de plus de 100. En effet, la solution de stockage à froid n’utilise qu’environ 3 W lorsqu’elle est allumée (source) – à peine l’énergie d’une seule petite ampoule – là où un serveur de sauvegarde classique consomme souvent 30 W ou plus en continu (source). Sur une journée, cela équivaut à seulement quelques wattheures (Wh) consommés, contre plusieurs centaines de Wh pour une machine fonctionnant 24h/24. On obtient ainsi jusqu’à 100 fois moins d’énergie utilisée (par exemple ~3 Wh/jour contre ~300 Wh/jour dans une configuration classique).
Une infrastructure éco-conçue et sans climatisation
Une autre force du stockage à froid écologique réside dans l’infrastructure matérielle et architecturale qui l’accompagne. Ici, tout est pensé pour minimiser l’impact environnemental :
Matériel basse consommation, issu du ré-emploi : Le cœur du système est un mini-ordinateur de type Raspberry Pi, un appareil de la taille d’une carte de crédit qui consomme seulement quelques watts mais suffit amplement pour gérer des sauvegardes, archiver des données. Ce petit ordinateur, couplé à un disque dur 2,5” économe en énergie, constitue un serveur silencieux et frugal.
Alimentation solaire et autonomie énergétique : Le dispositif peut être alimenté par une installation solaire, cette énergie est utilisée en priorité. Vous pouvez choisir le mode de fonctionnement selon vos critères (énergie solaire prioritaire, exclusivement du solaire…)
Local bioclimatique : Le matériel de sauvegarde est hébergé dans un bâtiment éco-construit en adobe (des briques de terre crue façonnées à partir de terre locale). Ce local a été conçu en auto-construction selon les principes bioclimatiques : il est orienté plein nord pour éviter l’exposition directe au soleil, ce qui le maintient naturellement frais. Les murs en terre crue offrent une excellente inertie thermique, gardant l’intérieur à une température stable. De plus, une ventilation naturelle a été mise en place grâce à des « chapeaux de cheminée » (éoliennes statiques sur le toit) qui créent un tirage d’air frais constant. Résultat : même en été, la température à l’intérieur reste modérée, nul besoin de climatisation artificielle.
Accéder à une interface de démonstration simple
Le mode SFTP distant n’est pas permis ici pour la démonstration, vous avez seulement un accès HTTP et de façon limitée en quota disque.
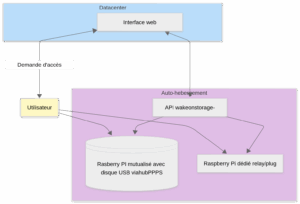
WakeOnStorage permet d’accéder à distance à des ressources de stockage ou à des petits serveurs domestiques, tout en les maintenant éteints la plupart du temps pour économiser l’énergie, réduire la surface d’attaque
Le principe repose sur deux composants complémentaires :
Interface en ligne (wakeonstorage.retzo.net) — accessible depuis Internet — qui permet à l’utilisateur de visualiser l’état de ses ressources, de les allumer temporairement, et d’y accéder une fois disponibles.
API locale (wakeonstorage-local) — installée sur le réseau local — qui communique avec le matériel (disques USB contrôlé par PPPS, Raspberry Pi allumé par relais…) pour exécuter les ordres.
By mermaid
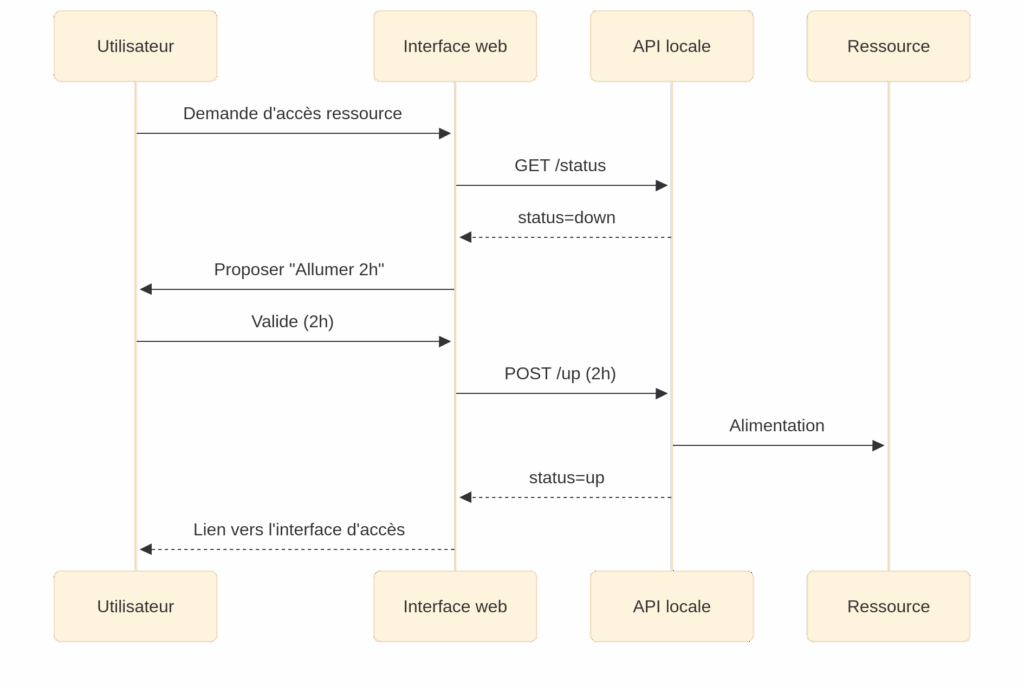
Lorsqu’un utilisateur demande une ressource, l’interface interroge l’API locale. Si la ressource est déjà allumée, elle devient directement accessible. Si elle est éteinte, l’interface propose de l’allumer pour une durée déterminée (par exemple 2 heures).
L’API locale envoie alors les commandes nécessaires : activation d’un relai pour démarrer un Raspberry Pi, ou alimentation d’un disque dur via un hub USB pilotable (PPPS) Une fois la ressource allumée, l’accès est temporairement autorisé.
Ce fonctionnement en deux niveaux garantit la sécurité, la sobriété énergétique et l’autonomie : aucune ressource n’est inutilement allumée, et tout reste sous le contrôle de l’utilisateur.
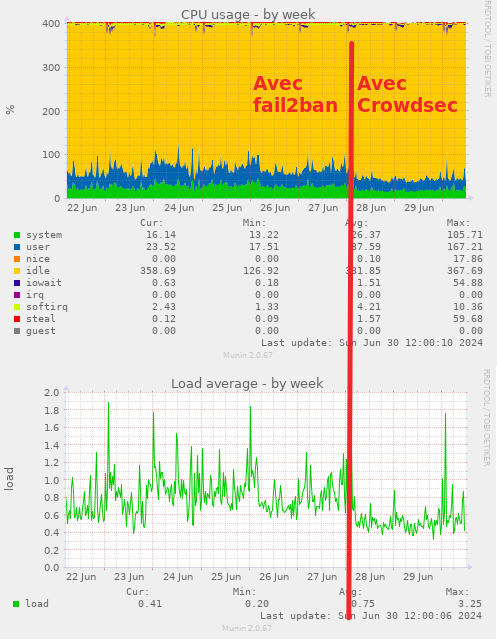
Je suis passé de fail2ban (que j’utilise depuis lonnngtemps) à Crowdsec pour les raisons suivantes :
fail2ban est (très) gourmand en ressource serveur (trop)
Crowdsec dispose d’un volet « scénario » que je trouve bien malin et qui le rend « plus intelligent » et permet de mutualiser les IP frauduleuse.
Au final je bloque certainement plus d’attaques pour bien moins de CPU (surtout) consommés.
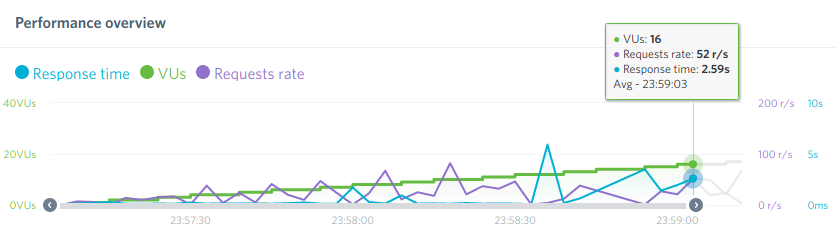
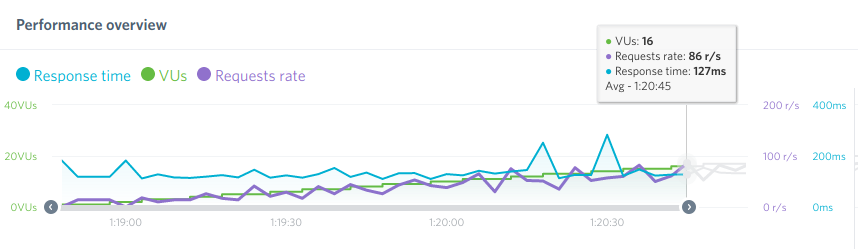
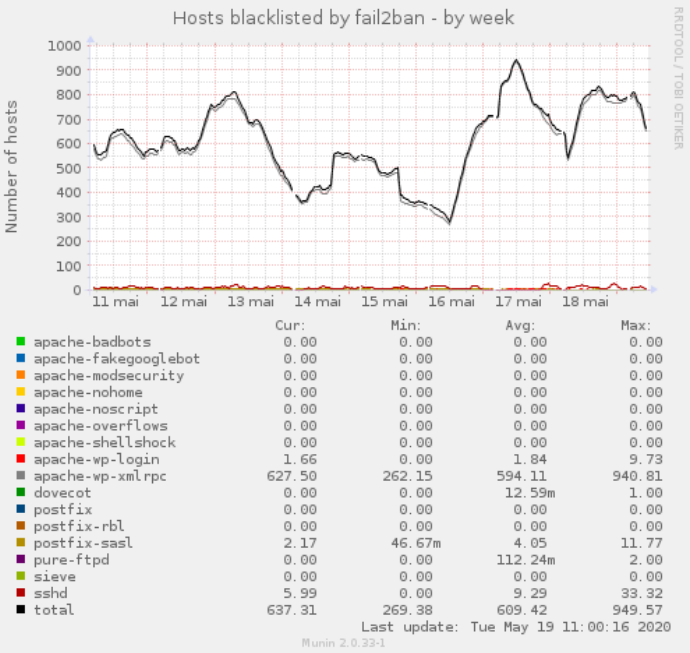
C’est plutôt flagrant sur le côté « économie de ressources CPU » sur les graph :
Comparatif stats (munin) avant avec fail2ban et après avec crowdsec
Mise en œuvre
Mon contexte : des serveurs avec le panel ISPconfig (ce dernier écoute sur le port 8080 – important pour la suite) sur Debian 11.
Je ne vais pas détailler ici ce qu’il y a dans la documentation Crowdsec, d’autant que ça peut changer. Pour mon OS (Debian) actuellement c’est :
# Installation du dépôt
curl -s https://install.crowdsec.net | sudo sh
# Installation de crowdsec
apt install crowdsec
Du coup, comme ISPconfig écoute déjà sur le port 8080 et que Crowdsec utilise ce port pour son API il faut modifier celui-ci (moi je passe à 8079) :
sed -i -e "s/8080/8079/g" /etc/crowdsec/config.yaml
sed -i -e "s/8080/8079/g" /etc/crowdsec/local_api_credentials.yaml
systemctl restart crowdsec
ISPconfig n’utilise pas logrotate pour la rotation de log apache, il a son propre processus intégré. Pour que Crowdsec puisse lire tout les logs HTTP (ici apache) il va falloir lui donner le chemin. MAIS. ISPconfig nomme les logs par date et créer un lien symbolique vers « access.log » :
# ls /var/log/ispconfig/httpd/david.mercereau.info/ -la
total 173480
drwxr-xr-x 2 root root 4096 30 juin 12:19 .
drwxr-xr-x 176 root root 12288 21 juin 16:05 ..
[...]
-rw-r--r-- 1 root root 4712747 29 juin 23:59 20240629-access.log
-rw-r--r-- 1 root root 2836678 30 juin 14:08 20240630-access.log
lrwxrwxrwx 1 root root 19 30 juin 12:19 access.log -> 20240630-access.log
lrwxrwxrwx 1 root root 55 30 juin 00:12 yesterday-access.log -> /var/www/clients/client3/web196/log/20240629-access.log
Mais pour que le « nouveau » log soit pris en considération je fais un restart du service crowdsec à 0:20 (la rotation ayant lieu à ~0:10) chez moi au vu des date de création des fichiers de logs :
20 0 * * * systemctl restart crowdsec
C’est un peu du bricolage mais c’est le meilleurs compromis que j’ai jusque là.
EDIT : j’ai changé mon fusil d’épaule pour (aussi) ménager le nombre de fichier suivi par crowdsec (j’ai un serveur avec 200 vhost). En effet je me suis rendu compte que /var/log/apache2/other_vhosts_access.log était surveillé via /etc/crowdsec/acquis.yaml donc il y avait double surveillance des access. J’ai donc juste ajouté les « error.log » dans mon /etc/crowdsec/acquis.d/ispconfig.yaml
A ce stade il n’y a aucun ‘effet’ (pas de blocage). De mon côté j’utilise le firewall iptables donc j’ai utiliser le bouncer qui va bien pour lui :
apt install crowdsec-firewall-bouncer-iptables
De la même façon on change le port pour joindre l’API
sed -i -e "s/8080/8079/g" /etc/crowdsec/bouncers/crowdsec-firewall-bouncer.yaml
systemctl restart crowdsec-firewall-bouncer
Des commandes utiles :
cscli decision list
cscli alert list
# Pour voir toutes les IP blacklisté (intégrant les IP renvoyé par l'API centrale crowdsec
ipset list crowdsec-blacklists
# Supprimer une IP bloqué
cscli decisions delete -i x.x.x.x
Du fait de la « mutualisation » des blacklistes il y a de la data qui est envoyé chez un tiers… bon même si la société est Française le site est hébergé à San Francisco (mention légal) Typiquement le modèle économique est de récupérer de la data (les IP malveillantes) sur les « crowdsec community » pour détecter des intrusions et vendre des bases d’IP à bloquer aux autres… (note : ce partage vers l’API centrale est désactivable : FAQ / Troubleshooting | CrowdSec)
Le dashboard local est déprécié Cscli dashboard deprecation | CrowdSec au profil de l’APP en ligne crowdsec non open source pour le coup… (pour le coup c’est pas indispensable à l’usage de Crowdsec)
J’ai l’impression que le modèle économique se dessine et que ça se ferme un peu…
Toute proportion gardé bien sûr, on parle d’IP malveillante et non de data utilisateur… Je voudrais pas faire mon « libo-terroriste » hein
Plugin Munin
Moi j’aime bien monitorer ce qui ce passe et comme le dashboard local Crowdsec n’est plus maintenu, a minima j’ai fais un plugin pour avoir des graph’ dans Munin :
WordPress occupe une part très importante dans l’usage des CMS à l’heure ou j’écris ce billet (62%). Voilà ce qui peut l’expliquer à mon sens :
Simple d’utilisation côté utilisateur
Plutôt simple côté développeur
Un nombre incalculable de thèmes et de plugins sont à disposition (communauté conséquente).
Mais il a aussi les défaut de ses qualités :
Côté utilisation de ressources énergétiques (serveur), WordPress est une catastrophe… Surtout dès qu’on lui ajoute des plugins (qui n’en ajoute pas ?).
Côté sécurité, il est très attaqué (car très utilisé). Le sport préféré des hackers, c’est le brute force…
Je vais tâcher de balayer ici mes trucs pour transformer un wordpress énergivore en wordpress sobre et sécurisé 🙂
Transformer en site statique (parfait pour les sites vitrines)
Un site « statique » c’est quoi ? C’est un site ou le code est uniquement exécuté sur le client et le serveur ne fait rien d’autre que « servir la page ». Alors qu’un site dynamique par opposition (sous wordpress pour l’exemple) va générer des pages « à la volée » et donc utiliser des ressources sur le serveur.
Mon parti-pris, c’est de convertir le wordpress « visible pour les visiteurs » en site statique « html ». L’utilisateur continue d’utiliser / d’alimenter son site via l’interface (bien faite et connue) wordpress, mais le visiteur lui ce qu’il voit c’est un site « html », sans aucun code dynamique (php ici) exécuté. De cette façon :
Le site est inattaquable par les hackers/spameurs, il n’y a plus de code dynamique, donc plus de moyen de corrompre le site / le serveur
L’affichage pour le visiteur est beaucoup plus rapide.
Le serveur consomme beaucoup moins de ressources (moins d’électricité, plus petit serveur…).
Les utilisateurs qui connaissent déjà wordpress ne sont pas bouleversés / impactés par cette optimisation.
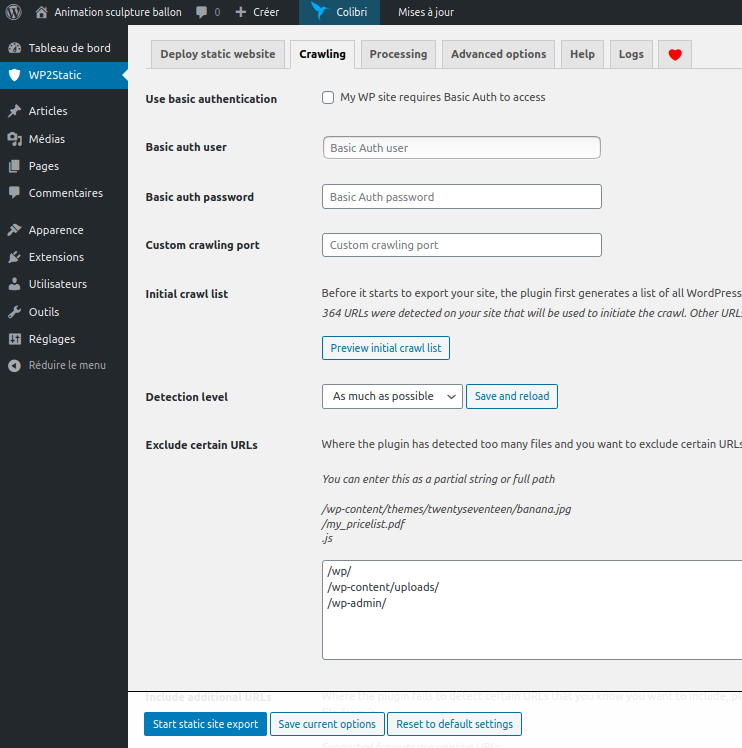
Pour cela j’utilise un plugin wordpress qui s’appelle wp2static. Voici la structure du répertoire « web » qui est la racine du site :
/wp/ : site wordpress avec le plugin wp2static. Adresse utilisée par l’administrateur du site pour faire ces modifications
/static/ : le site statique généré par le plugin
/.htaccess : contient les redirections pour que le visiteur ne voit pas de différence
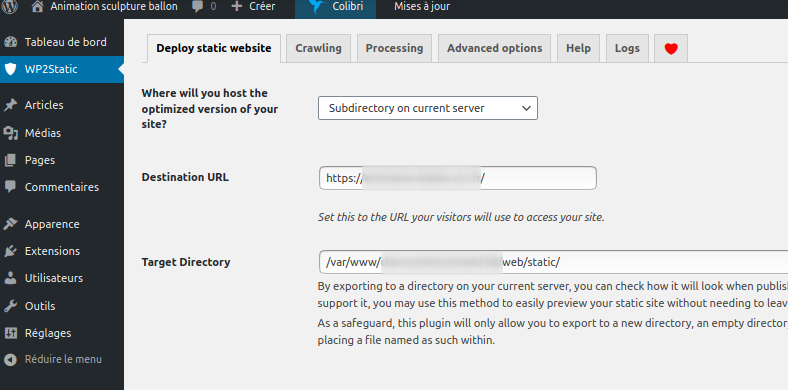
Dans le wordpress installé dans /wp/ rendez -vous dans wp2statics et configuré :
Where will you host the optimized version of your site? : Subdirectory
Quand c’est fait, vous pouvez cliquer sur Start Static Export.
Ajouter dans votre configuration apache ou dans un .htaccess à la racine du site :
RewriteEngine on
# Pas de ré-écriture pour le contenu uploadé (images,
RewriteRule ^/wp-content/uploads/(.*)$ /wp/wp-content/uploads//$1 [L]
# Rediriger toutes les requêtes vers /static sauf quand l'accès est souhaité sur le site wordpress original (/wp)
RewriteCond %{REQUEST_URI} !^/wp/
RewriteRule ^(.*)$ /static/$1 [L]
Inconvénient majeur de ce type de « transformation » en site full static
A chaque modification l’utilisateur doit penser à re-générer le site statique
Le contenu dynamique (formulaire de contact / commentaire) est impossible :
Pour les commentaires, c’est possible avec des commentaires chargés en Javascript, typiquement HashOver Next (alternative auto-hébergable à DISQUS). J’ai fait un script de migration WordPress > HashOver : wp2hashover
Pour les commentaires, il est possible d’utiliser des formulaires en iframe ou formulaire javascript/ajax
La solution wp2static n’était pas complètement satisfaisante et j’ai continué mes recherches. En testant le plugin W3 Total Cache, je me suis aperçu qu’il faisait exactement ce que je cherchais à faire et même plus !
Après paramétrage, j’ai trouvé ceci dans le fichier .htaccess :
Si la page HTML static a été générée (le fichier existe) dans /var/www/decroissant-au-beurre.com/web/wp-content/cache/page_enhanced/decroissant-au-beurre.com/services/_index_ssl.html (pour l’appel à https://decroissant-au-beurre.com/services/ alors on l’appelle directement (pas d’exécution de code PHP… ) SINON on appelle la page « normale » dans wordpress et celui-ci génère la page de cache /static pour le prochain visiteur
Dès qu’il y a une requête POST, le cache n’est pas appelé. Donc tous les formulaires restent compatibles avec le cache et seules les pages de résultats ne seront pas tirées du cache.
Ca veut dire qu’a performance égale avec la solution précédente, ce plugin fait mieux car il gomme les défauts précédents et permet de continuer d’utiliser des formulaires/les commentaires.
C’est parfait ! Le cache peut aussi être stocké via memcache et non sur disque (ce qui rend l’accès / l’affichage encore plus rapide (d’autres technologies possibles : APC / Xcache…)
Les fonctionnalités supplémentaires :
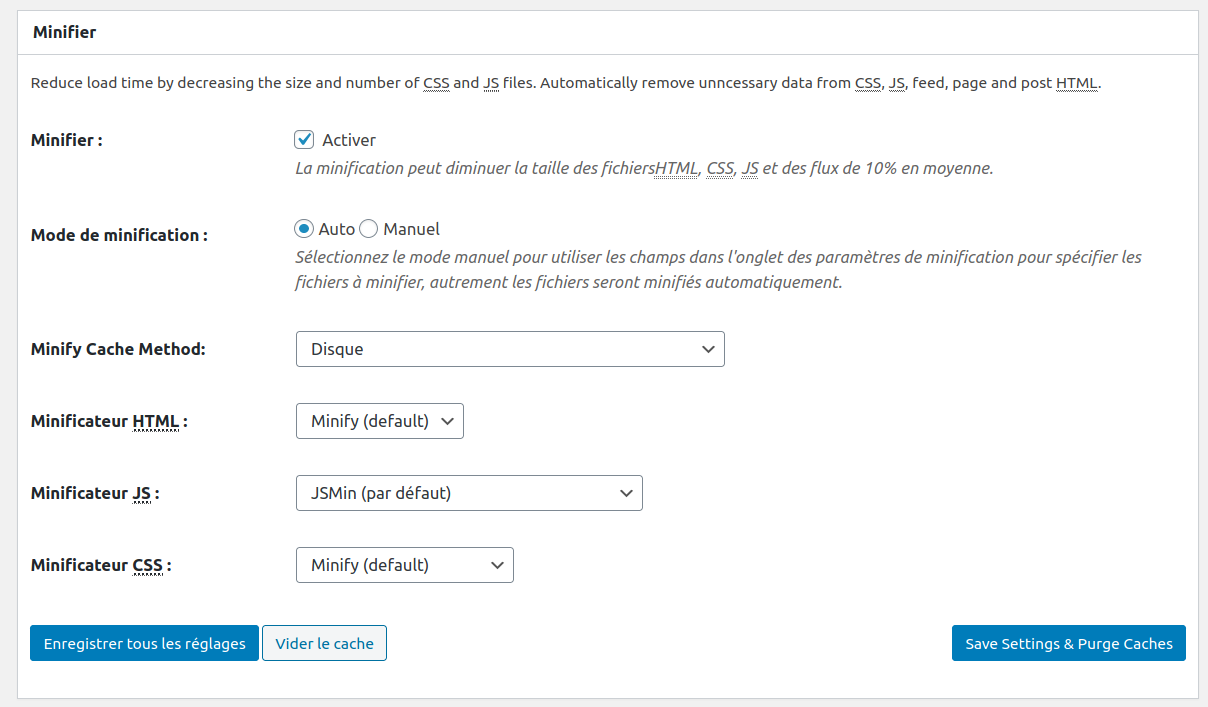
Minifier : diminuer trafic réseau
W3 Total Cache propose une fonctionnalité de Minification
minifier signifie réduire la taille du code. C’est un processus très utilisé en programmation web pour réduire la taille d’un programme à télécharger depuis un serveur et ainsi réduire l’encombrement du réseau. Cela peut aussi être considéré comme une forme d’offuscation du code.
Pour cela on supprime tous les commentaires et les espaces qui ne gêneront pas le bon fonctionnement de l’application. On remplace aussi le nom des variables interne à l’application pour les réduire à un seul ou deux caractères. Il est aussi possible d’utiliser certaines écritures compactes propres aux langages (couleur en hexadécimal, raccourcis…)
https://fr.wikipedia.org/wiki/Minification
Si on analyse le code après avoir activé la Minification on observe :
Vous pouvez minifier tout ou partie du code (HTML/ CSS / Javascript…). Certains plugins peuvent ne plus fonctionner à cause de la minification. Il est donc important de tester votre site après avoir activé ces options.
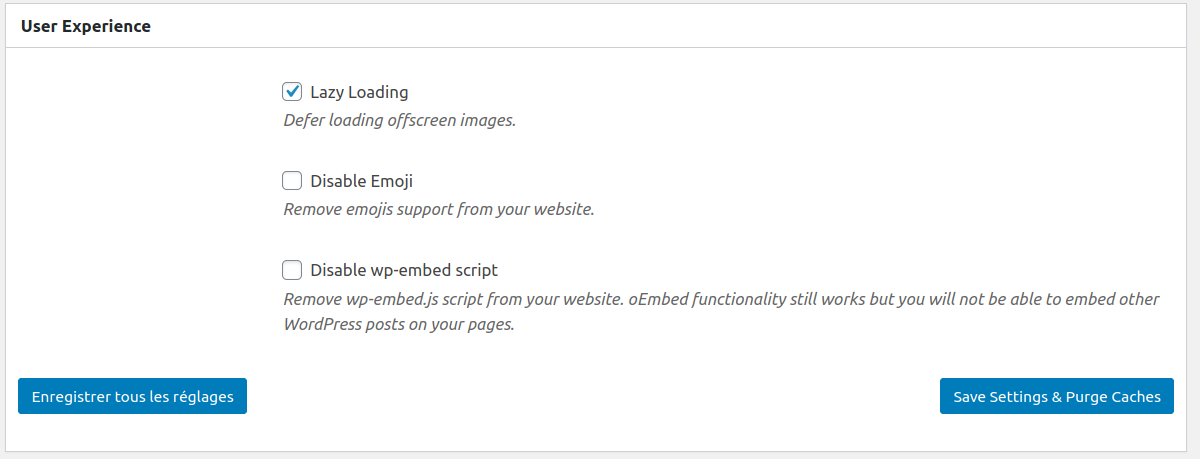
Lazy Loading : Afficher les images au besoin
Si vous avez un site très long, il est possible que des images soient présentes en bas de page. Il est pertinent de ne charger ces pages qu’au besoin (que si vous allez jusqu’en bas de la page). Et bien la fonction Lazy Loading permet cela.
Cette fonctionnalité permet aussi un gain non négligeable de bande passante.
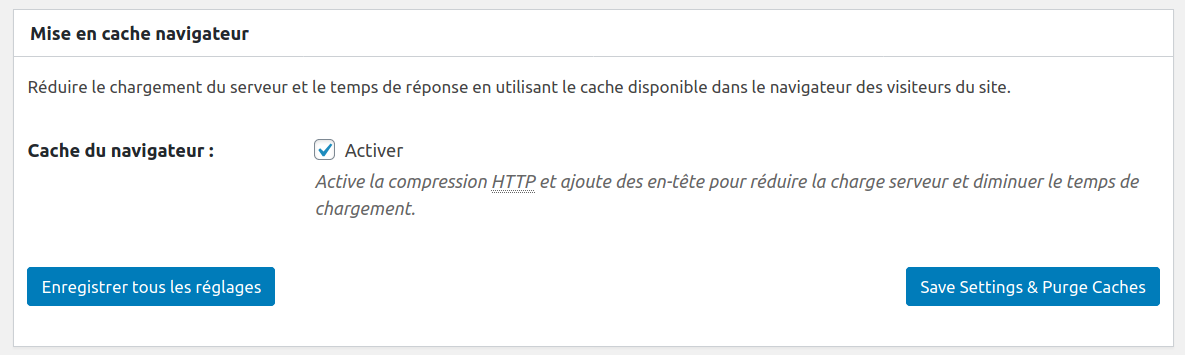
Mise en cache navigateur
Vous pouvez améliorer les entêtes navigateurs en spécifiant à celui-ci des dates d’expiration de fichier. De cette façon il ne va pas retourner charger la/les pages sur le serveur en cas de nouvelles visites.
Mesures performance
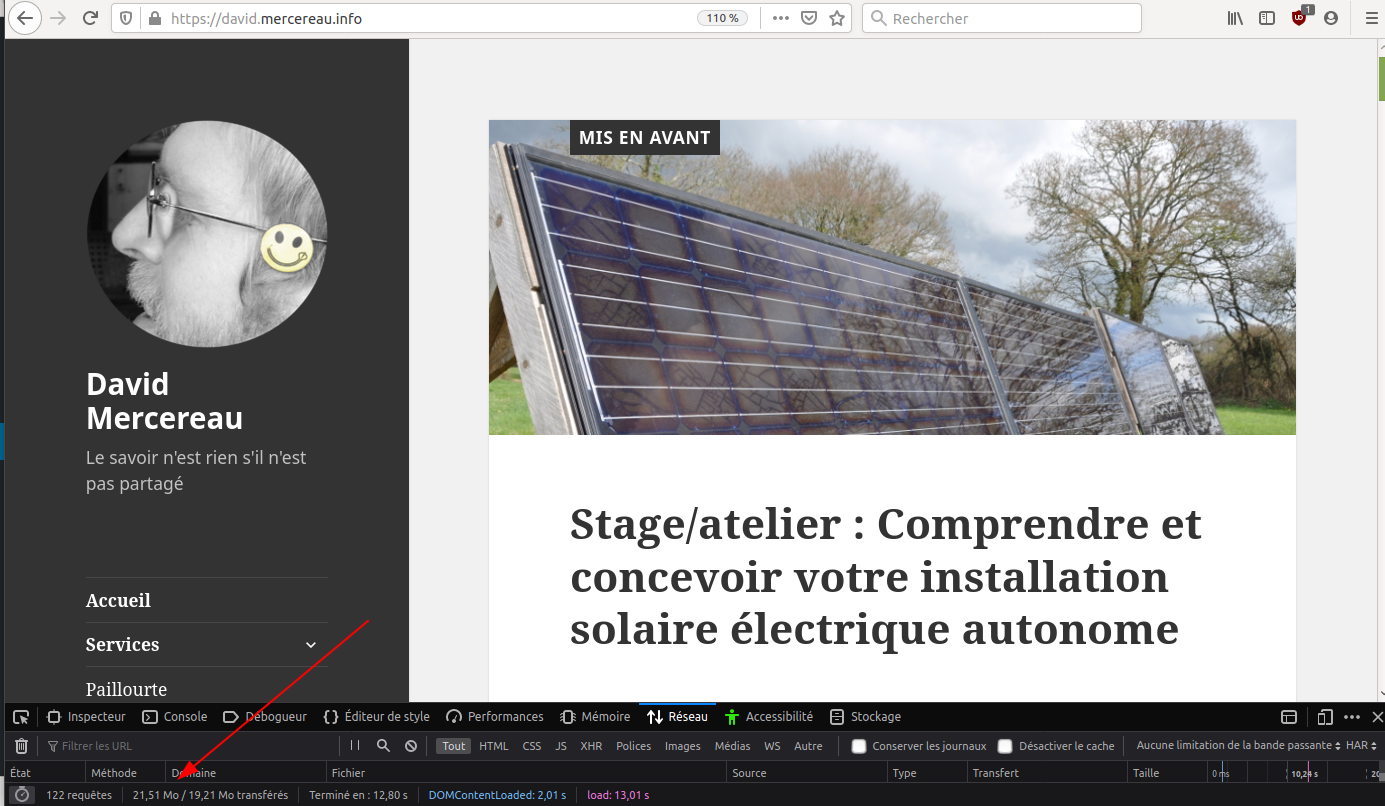
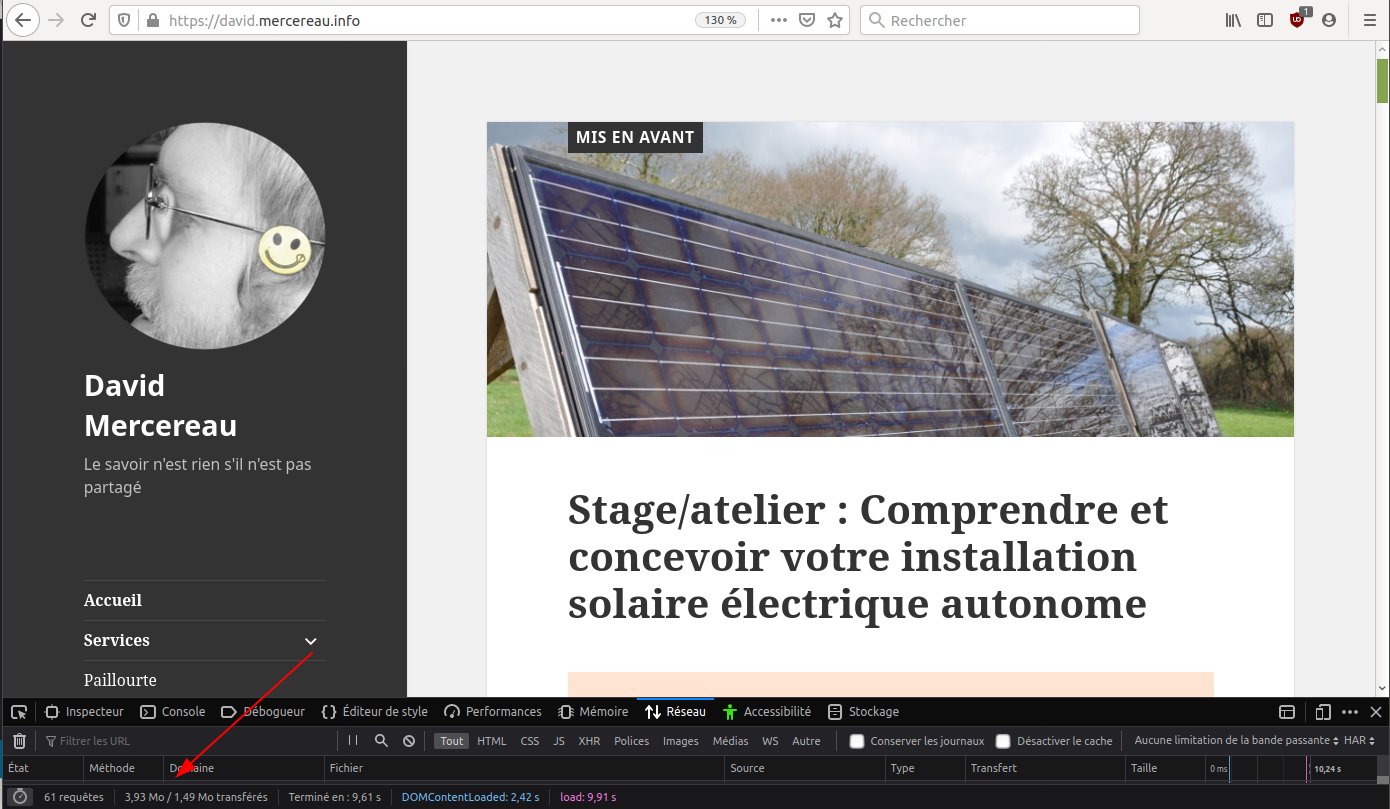
Voilà un stress test (envoi de requêtes massives) du même site avec ou sans génération en site statique (fait avec W3 total cache ici) :
WordPress sans optimisation
Avec cache/transformé en statique
On constate que c’est 20 fois plus rapide à l’affichage et que c’est plutôt constant. Est-ce que c’est 20 fois moins énergivore ? ça c’est difficile à mesurer mais c’est forcément moins…
Voici ci-après le poids de chargement d’une même page sans optimisation et avec Lazy Loading + Minification
Sans optimisation : 21,5
Avec Minification + Lazy : 3,9Mo
Sans optimisation : 21,5Mo
Avec Minification et Lazy : 3,9Mo
Soit 5,5 fois moins lourd…
Sécurité
Le minimum pour sécuriser un wordpress c’est :
Faire les mises à jour (de nombreux plugins existent pour automatiser cela)
Ne pas utiliser « admin » en nom d’utilisateur admin
Avoir des mots de passe forts
Bloquer les tentatives de brutes forces :
WordPress se fait pas mal attaquer du fait qu’il soit populaire. La principale attaque (hors SPAM sur les commentaires) est faite par brute-force sur la page wp-login.php et xmlrpc. J’ai consacré un article dédié pour intégrer les logs de WordPress dans Fail2ban, et ainsi pouvoir bloquer les tentatives au niveau firewall : WordPress & fail2ban : stopper la brute-force « POST /wp-login.php » (uniquement possible sur un hébergement dédié). C’est particulièrement efficace comme vous pouvez le voir sur ce graphique :
Graphique fail2ban sur 1 semaine
Gestion serveur mutualisé
Si vous gérez un serveur mutualisé, vous pouvez déployer le plugin de cache et faire les mise à jour de tous les wordpress installé sur votre serveur avec wp-cli-isp (taillé pour les serveurs sous ISPconfig, mais c’est adaptable)
Je partage ici mon script de firewall iptable. C’est un script « à l’ancienne », dans du bash… ça fait le taf, mais rien de bien transsudant. En gros :
On ferme tout les ports sauf ceux qui nous intéresse (80, 25, icmp…)
Petite fonction pour ouvrir les ports mis en écoute sur Portsentry. Portsentry c’est un petit logiciel de sécurité en mode « pot de miel ». On met des ports en écoute mais il n’y a rien derrière. Dès que quelqu’un tente de s’y connecter (un robot ou quelqu’un de malveillant), ça bloque son IP dans le firewall pour un temps donnée. C’est radical si vous déplacez le port SSH du 22 vers autre chose et que vous mettez Portsentry à écouter (entre autre) sur le 22…
Mode maintenance du serveur web (lancé via ./iptables.sh maintenance). Il permet de mettre une page de maintenance pour tout le monde sauf pour vous (j’explique en détail dans cet article)
#!/bin/bash
## IP :
# Chez moi
MOI="A.A.A.A"
# Mon serveur
SRV1="X.X.X.X"
IPT="/sbin/iptables"
PORTSENTRYCONF="/etc/portsentry/portsentry.conf"
export IPT PORTSENTRYCONF
function portsentryOpen() {
. ${PORTSENTRYCONF}
IFS=',' read -ra TCP_PORTS_SPLIT <<< "${TCP_PORTS}"
for TCP_PORT in "${TCP_PORTS_SPLIT[@]}"; do
${IPT} -A INPUT -p tcp --dport ${TCP_PORT} -j ACCEPT
done
IFS=',' read -ra UDP_PORTS_SPLIT <<< "${UDP_PORTS}"
for UDP_PORT in "${UDP_PORTS_SPLIT[@]}"; do
${IPT} -A INPUT -p udp --dport ${UDP_PORT} -j ACCEPT
done
}
# Remise a 0
${IPT} -F
${IPT} -t nat -F
# Les connexions entrantes sont bloquées par défaut
${IPT} -P INPUT DROP
# Les connexions destinées à être routées sont acceptées par défaut
${IPT} -P FORWARD ACCEPT
# Les connexions sortantes sont acceptées par défaut
${IPT} -P OUTPUT ACCEPT
######################
# Règles de filtrage #
######################
# Nous précisons ici des règles spécifiques pour les paquets vérifiant
# certaines conditions.
# Pas de filtrage sur l'interface de "loopback"
${IPT} -A INPUT -i lo -j ACCEPT
# Accepter le protocole ICMP (notamment le ping)
${IPT} -A INPUT -p icmp -j ACCEPT
# Accepter les packets entrants relatifs à des connexions déjà
# établies : cela va plus vite que de devoir réexaminer toutes
# les règles pour chaque paquet.
${IPT} -A INPUT -m state --state RELATED,ESTABLISHED -j ACCEPT
# ftp
${IPT} -A INPUT -p tcp --dport 20 -j ACCEPT
${IPT} -A INPUT -p tcp --dport 21 -j ACCEPT
# Préalabielemnt, pour pure-ftpd : echo "29700 29750" > /etc/pure-ftpd/conf/PassivePortRange ${IPT} -A INPUT -p tcp --dport 29700:29750 -j ACCEPT
# SSH
${IPT} -A INPUT -p tcp --dport 222 -j ACCEPT
# NTP
${IPT} -A INPUT -p udp --dport 123 -j ACCEPT
# smtp
${IPT} -A INPUT -p tcp --dport smtp -j ACCEPT
# Pour test bricolage smtp
${IPT} -A INPUT -p tcp --dport 587 -j ACCEPT
# imap(s)
${IPT} -A INPUT -p tcp --dport 143 -j ACCEPT
${IPT} -A INPUT -p tcp --dport 993 -j ACCEPT
# sieve
${IPT} -A INPUT -p tcp --dport 4190 -j ACCEPT
# dns
${IPT} -A INPUT -p tcp --dport domain -j ACCEPT
${IPT} -A INPUT -p udp --dport domain -j ACCEPT
# http
${IPT} -A INPUT -p tcp --dport http -j ACCEPT
# https
${IPT} -A INPUT -p tcp --dport https -j ACCEPT
# Maintenance
if [ "$1" == "maintenance" ] ; then
echo "Maintenance On"
/usr/sbin/service lighttpd start
${IPT} -A INPUT -p tcp --dport 81 -j ACCEPT
${IPT} -t nat -A PREROUTING \! -s ${MOI} -p tcp --dport 80 -j DNAT --to-destination ${SRV1}:81
${IPT} -t nat -A POSTROUTING -j MASQUERADE
elif [ -f "/var/run/lighttpd.pid" ] ; then
echo "Maintenance Off"
/usr/sbin/service lighttpd stop
fi
# Portsentry
if [ -f ${PORTSENTRYCONF} ] ; then
portsentryOpen ${IPT} ${PORTSENTRYCONF}
fi
# End
${IPT} -A INPUT -j LOG --log-prefix "iptables denied: " --log-level 4
${IPT} -A INPUT -j REJECT
# Si vous utilisez fail2ban, relancé à la fin du script :
#/usr/sbin/service fail2ban restart
EDIT 24/02/2015 : ‘Il n’est plus nécessaire d’utiliser cloudfiles comme backend pour duplicity. À la place, il faut utiliser un backend spécial hubic intégré à duplicity récemment »voir le commentaire de blankoworld
EDIT 02/2015 : suppression du « DeprecationWarning » dans le log.
Mon ADSL est depuis peut chez OVH. De ce fait je bénéficie d’un compte hubiC avec un espace de stockage d’1To. Quelle aubaine pour des sauvegardes ! Mais bon donner mes mails, mes sites, mes documents administratifs à un tiers… bof bof. Il faudrait un minimum de chiffrage !
python-cloudfiles-hubic est nécessaire car duplicity n’intègre pas nativement le service cloud « HubiC » pour une sombre histoire de protocole d’authentification non standard de la part d’OVH (détail par l’auteur)
aptitude install python-setuptools git
cd /usr/src
git clone https://github.com/Gu1/python-cloudfiles-hubic.git
cd python-cloudfiles-hubic
python setup.py install
Utilisation
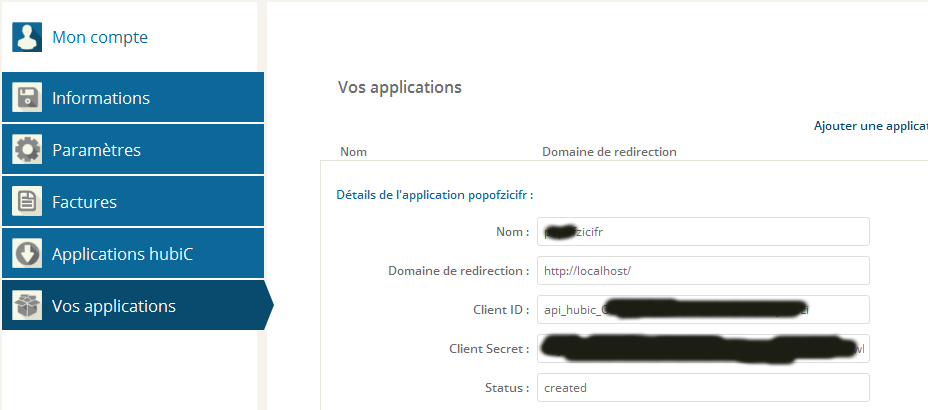
Dans vos paramètre sur hubic.com dans votre menu « Vos application » il va falloir ajouter une application :
Nom : cequevousvoulez
Domaine de redirection : http://localhost/
Quand l’application est créer récupérer le « client id » ainsi que le « client secret » dans l’interface
Quelques petits tests pour la prise en main :
# Désactiver le bash_history (c'est pénible avec les mots de passes)
unset HISTFILE
# Les variables
export CLOUDFILES_USERNAME=toto@toujours.lui
export CLOUDFILES_APIKEY=je.vais.pas.vous.donner.le.mot.de.passe.de.toto
# CLOUDFILES_AUTHURL="hubic|client id|client secret|http://localhost/"
export CLOUDFILES_AUTHURL="hubic|api_hubic_XXXX|YYYYY|http://localhost/"
# Sauvegarde
duplicity /root cf+http://default
# Observer l'état
duplicity collection-status cf+http://default
# Liste les fichiers distants
duplicity list-current-files cf+http://default
# Test la restauration d'un fichier
duplicity --file-to-restore .bash_alias cf+http://default /tmp/bash_alias_recup
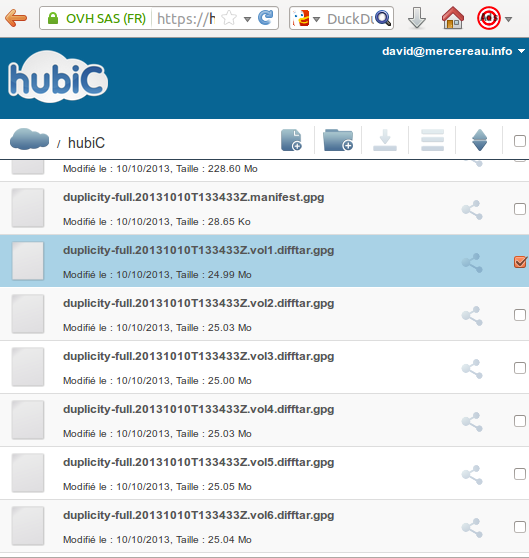
Rendez-vous ensuite dans votre interface hubiC. Et là normalement il y a plein de fichier duplicity-BLABLA-blabla.bla ! On supprime tout ! (c’était juste pour les tests)
Il ne semble pas possible d’écrire dans un sous répertoire. Mais, comme je l’ai signalé dans mon commentaire, il semble possible d’écrire dans un autre « container » sur hubiC (autre que default). Il ne sera visible qu’après modification de l’URL. Exemple si vous avez écrit dans le conteneur backup rendez vous sur l’URL : https://hubic.com/home/browser/#backup
Le script
Voici mon script :
#!/bin/bash
###################################
## Backup sur HubiC avec duplicity
# Script sous licence BEERWARE
# Version 0.4.1 02/2015
###################################
set -eu
##### Paramètres
# Utilisateur Hubic
HUBICUSER="leuserdevotrehubic"
# Mot de passe HubiC
HUBICPASSWORD="lemotdepassedevotrehubic"
# Application client id Hubic
HUBICAPPID="api_hubic_XXXXX"
# Application client secret Hubic
HUBICAPPSECRET="YYYYYY"
# Application domaine de redirection Hubic
HUBICAPPURLREDIRECT="http://localhost/"
# Liste à sauvegarder (voir le man duplicity avec le filelist)
DUPLICITYFILELIST="/etc/backup-`hostname`.filelist"
# Passphrase pour le chiffrement
PASSPHRASE="VotrePassPhraseDeOufQueYaQueVousEtVousSeulQuiSavez:-p"
# Fréquence des sauvegardes complètes
FULLIFOLDERTHAN="1W"
# Rétention des sauvegardes
RETENTION="2M"
# Log d'erreur
LOGERROR="/var/tmp/backup-hubic-error.log"
# Bin de duplicity
DUPLICITY_BIN="/usr/bin/duplicity"
# Email pour les erreurs (0 pour désactiver)
EMAIL="toto@mondomaine.com"
# Envoyer un rapport par email sur l'état des backup
RAPPORT=1
# Log d'erreur
exec 2> ${LOGERROR}
##### Début du script
function cleanup {
echo "exit..."
unset CLOUDFILES_USERNAME
unset CLOUDFILES_APIKEY
unset PASSPHRASE
grep -v "has been deprecated" ${LOGERROR} > ${LOGERROR}.tmp
mv ${LOGERROR}.tmp ${LOGERROR}
if [ "`stat --format %s ${LOGERROR}`" != "0" ] && [ "$EMAIL" != "0" ] ; then
cat ${LOGERROR} | mail -s "$0 - Error" ${EMAIL}
fi
}
trap cleanup EXIT
# Gentil avec le système
ionice -c3 -p$$ &>/dev/null
renice -n 19 -p $$ &>/dev/null
if ! [ -f ${DUPLICITYFILELIST} ] ; then
echo "Aucun fichier filelist : ${DUPLICITYFILELIST}"
exit 1
fi
export CLOUDFILES_USERNAME=${HUBICUSER}
export CLOUDFILES_APIKEY=${HUBICPASSWORD}
export CLOUDFILES_AUTHURL="hubic|${HUBICAPPID}|${HUBICAPPSECRET}|${HUBICAPPURLREDIRECT}"
export PASSPHRASE
# Backup
${DUPLICITY_BIN} --full-if-older-than ${FULLIFOLDERTHAN} / cf+http://default --include-globbing-filelist ${DUPLICITYFILELIST} --exclude '**'
# Suppression des vieux backups
${DUPLICITY_BIN} remove-older-than ${RETENTION} cf+http://default --force
# Rapport sur le backup
if [ "$RAPPORT" != "0" ] && [ "$EMAIL" != "0" ] ; then
${DUPLICITY_BIN} collection-status cf+http://default | mail -s "$0 - collection-status" ${EMAIL}
fi
unset CLOUDFILES_USERNAME
unset CLOUDFILES_APIKEY
unset PASSPHRASE
exit 0
A noter que mes bases de données sont dumpées à plat de façon indépendante du script de backup distant (par mysql_dump.sh)
Attention : les fichiers et répertoires à exclure doivent apparaître avant l’inclusion d’un répertoire parent. En effet, duplicity s’arrête à la première règle qui matche un chemin donné pour déterminer s’il doit l’inclure ou l’exclure. (sources)
WordPress étant très populaire il est (malheureusement) de fait très attaqué.. La principale (hors SPAM sur les commentaires) est faite par brute-force sur la page wp-login.php. Je l’avais déjà remarqué, mais j’ai récement eu des problèmes d’indisponibilités suite à plusieurs attaques venant de multiple adresse IP (l’attaque passant donc de brute-force à DDOS) J’ai donc dû réagir et pour ce faire j’ai configuré fail2ban pour bloquer les IP’s faisant plus de 6 tentatives de connexions sur tous les sites wordpress du serveur.
Configuration de fail2ban
Note : mon installation de fail2ban est existante et fonctionne déjà pour le FTP & le SSH
Créer le fichier /etc/fail2ban/jail.d/apache-wp-login.conf :
Pour finir : un restart du service fail2ban & vous n’avez plus qu’à tester en faisant plus de 6 tentatives de mot de passe sur la page votreblog/wp-admin/
$ service fail2ban restart
$ tail -f /var/log/fail2ban.log
2013-09-05 16:33:39,559 fail2ban.actions: WARNING [apache-wp-login] Ban XX.XX.XX.XX
Pour information, le lendemain 47 IP ont été bloquées grâce à ce système…
$ fail2ban-client status apache-wp-login Status for the jail: apache-wp-login |- Filter | |- Currently failed: 7 | |- Total failed: 59966 | `- File list: /var/log/apache2/mercereau.info/access.log `- Actions |- Currently banned: 0 |- Total banned: 4128 `- Banned IP list:
Si comme moi vous gérez un hébergement mutualiser vous pouvez ajouter un script qui toutes les nuits scan votre /var/www à la recherche de wp-login.php et ajout le log dans fail2ban. Ce script est adapté à l’architecture d’ISPconfig :
#!/bin/bash
# Détection des wordpress sur le serveur
# Ajout des logs du site en question dans fail2ban
# Fonctionne avec l'arbo du panel ISPconfig3
# A mettre en tâche planifié
fail2banConf='/etc/fail2ban/jail.d/apache-wp-login.conf'
echo -n "[apache-wp-login]
enabled = true
port = http,https
filter = apache-wp-login
maxretry = 8
logpath = " > $fail2banConf
find /var/www/clients -name wp-login.php | while IFS=$'\n' read f ; do
clientId=`echo $f | cut -d"/" -f5`
siteId=`echo $f | cut -d"/" -f6`
# Test si le lien symbolique n'est pas mort
readlink=`readlink /var/www/clients/$clientId/$siteId/log/access.log`
ls /var/www/clients/$clientId/$siteId/log/${readlink} &>/dev/null
if ! (($?)) ; then
echo " /var/www/clients/$clientId/$siteId/log/access.log " >> $fail2banConf
fi
done
/etc/init.d/fail2ban restart >/dev/null
Vous pouvez aussi faire la même chose pour bloquer wp-xmlrpc (qui est très sollicitée en brute force. Dans le script d’automatisation je télécharge les IP utilisé par JetPack (non pas que j’aime ce plugin mais certain de mes utilisateurs l’utilise et c’est bloquant pour xmlrpc…
#!/bin/bash
# Détection des wordpress sur le serveur
# Ajout des logs du site en question dans fail2ban
# Fonctionne avec l'arbo du panel ISPconfig3
# A mettre en tâche planifié
# https://wpchannel.com/wordpress/tutoriels-wordpress/lutter-attaques-ddos-xml-rpc-php-fail2ban/
cd /tmp
wget https://jetpack.com/ips-v4.txt
if ! (($?)) ; then
ips=`sed ':a;N;$!ba;s/\n/ /g' /tmp/ips-v4.txt`
else
ips=''
fi
fail2banConf='/etc/fail2ban/jail.d/apache-wp-xmlrpc.conf'
echo -n "[apache-wp-xmlrpc]
enabled = true
filter = apache-wp-xmlrpc
bantime = 86400
maxretry = 1
port = http,https
ignoreip = 127.0.0.1/8 ns1.wordpress.com ns2.wordpress.com ns3.wordpress.com ns4.wordpress.com jetpack.wordpress.com $ips
logpath = " > $fail2banConf
find /var/www/clients -name wp-login.php | while IFS=$'\n' read f ; do
clientId=`echo $f | cut -d"/" -f5`
siteId=`echo $f | cut -d"/" -f6`
# Test si le lien symbolique n'est pas mort
readlink=`readlink /var/www/clients/$clientId/$siteId/log/access.log`
ls /var/www/clients/$clientId/$siteId/log/${readlink} &>/dev/null
if ! (($?)) ; then
echo " /var/www/clients/$clientId/$siteId/log/access.log " >> $fail2banConf
fi
done
/etc/init.d/fail2ban restart >/dev/null
Et le fichier : /etc/fail2ban/filter.d/apache-wp-xmlrpc.conf
Modification de la configuration d’OpenDKIM (/etc/opendkim.conf) :
Socket inet:8891@localhost
LogWhy yes
MilterDebug 1
# Log to syslog
Syslog yes
# Required to use local socket with MTAs that access the socket as a non-
# privileged user (e.g. Postfix)
UMask 002
KeyTable /etc/dkim/KeyTable
SigningTable /etc/dkim/SigningTable
ExternalIgnoreList /etc/dkim/TrustedHosts
InternalHosts /etc/dkim/TrustedHosts
Il faut maintenant générer les clefs & ce script va nous y aider :
#!/bin/bash
# Script sous licence BEERWARE
SELECTOR="mail"
REPERTOIRE="/etc/dkim"
DOMAINE=$1
USERDKIM="opendkim"
GROUPDKIM="opendkim"
if ! [ -d "${REPERTOIRE}" ] ; then
echo "Le répertoire ${REPERTOIRE} n'existe pas."
exit 1
fi
if [ -z ${DOMAINE} ] ; then
echo "Vous devez avoir renseigner le domaine en argument du script."
exit 2
fi
if [ -d "${REPERTOIRE}/keys/${DOMAINE}" ] ; then
echo "Le répertoire ${REPERTOIRE}/keys/${DOMAINE} existe déjà... vous devez déjà avoir dû lancé le script."
exit 3
else
mkdir -p ${REPERTOIRE}/keys/${DOMAINE}
fi
opendkim-genkey -D ${REPERTOIRE}/keys/${DOMAINE} -r -d ${DOMAINE} -s ${SELECTOR}
chown ${USERDKIM}:${GROUPDKIM} ${REPERTOIRE}/keys/${DOMAINE}/${SELECTOR}.private
echo "${SELECTOR}._domainkey.${DOMAINE} ${DOMAINE}:${SELECTOR}:${REPERTOIRE}/keys/${DOMAINE}/${SELECTOR}.private" >> ${REPERTOIRE}/KeyTable
echo "${DOMAINE} ${SELECTOR}._domainkey.${DOMAINE}" >> ${REPERTOIRE}/SigningTable
echo "${DOMAINE}" >> ${REPERTOIRE}/TrustedHosts
if [ -f ${REPERTOIRE}/keys/${DOMAINE}/${SELECTOR}.txt ]; then
cat ${REPERTOIRE}/keys/${DOMAINE}/${SELECTOR}.txt
else
echo "Une erreur s'est produite !"
fi
Exemple d’utilisation du script :
$ ./addDkimKey.sh mercereau.info
mail._domainkey IN TXT "v=DKIM1; g=*; k=rsa; p=MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDEOxRe2sVbsmDYbnB1pRWdx5U6FgZiwUKRl0gPFmsgPNA035P7gBLmhXrmALeJLZv0n7ARkStoIvl/ZNAbUep/YUgMynW5q2fsh4Pa/q82ocPKRKGLBYTxFDa+tyhG0oi5pzI6d37Ji9M40c5DgD/2QqTfyY5ywLqKG47+HuivJQIDAQAB" ; ----- DKIM mail for mercereau.info
Le script vous sort l’enregistrement DNS a ajouter pour terminer la configuration
On redémarre les services :
$ service opendkim restart
$ service postfix restart
Ce tuto à été très fortement inspiré par le tuto de isalo.org
En continuant à utiliser le site, vous acceptez l’utilisation des cookies (au chocolat) Plus d’informations
Les cookies sont utilisés à des fin de statistique de visite du blog sur une plateforme indépendante que j'héberge moi même. Les statistiques sot faites avec un logiciel libre. Aucune information n'est redistribué à google ou autre. Je suis seul autorisé à lire ces informations